
Go into Go Programming Language-Basi
Basic Grammar
Variables
-
Golang is a strongly typed language.
-
Type
stringis a built-in type. It can use+and=. -
Explicitly declare Var
-
:= type(name)
-
varname type
-
-
const(the same meaning as other languages)vardoes not have a specified type when it is declared, since it will be set automatedly according to the context when thevaris used.
if-else
-
In Golang, if-else has a similar grammar as other languages.
-
Be careful:
-
There is no
()afterif, and if so, the compiler will automatedly remove it. -
There must be
{}afterif, even though there is only one line after it.
-
The editor did not save automatedly and the system crashed down, so there shall be another 500 words 😭.
Loop
-
There is only
forin Golang. -
Writing down
forwithout anything following has the same meaning aswhile. -
The loop grammar is similar to C.
Error
-
In Golang, we can know which function returns an
errorand use if-else to deal with it.- It is different from Java. In Java, we use Exception Class, and if an exception is thrown out, we can use
try-catchto deal with it.
- It is different from Java. In Java, we use Exception Class, and if an exception is thrown out, we can use
-
Add
errorto the return parameter of a function
strings

strings formatting
-

-
Be careful:
-
It is different from C, as we just use
%vto hold a place, and it is a little bit like Java. -
If we use
+or#, we can get more detailed information.
-
JSON
-

-
Be careful: we need to make sure the public fields (like Home, Age, and Hobby in the above codes) come with initial capitalization. If we want the
printresult is a low capitalization, we can use the tagjson. -
After using
json.Marshalto analyze thea, we may get a byte list.- After that, we can use forced type conversion to get a string-type result.
-
For the same reasons, we can use
Unmarshalto convert a string into JSON.
Time
-

-
The above codes contain almost all common functions.
-
Be careful:
-
The formatting of the time is not YY MM DD or something like that, but a specific time “2006-01-02 15:04:05”
-
According to some open information, this particular time is generated according to the customary American time
January 2ed 15:04:05 2006
1月2日 下午3点4分5秒 06年
-
-
Number
-
-
The first parameter is the string to be converted, the second parameter is binary, and the third parameter is the precision
- When the second parameter is 0, it means that it is automatically parsed and processed
-
Atoiis the default decimal conversion
Process
-
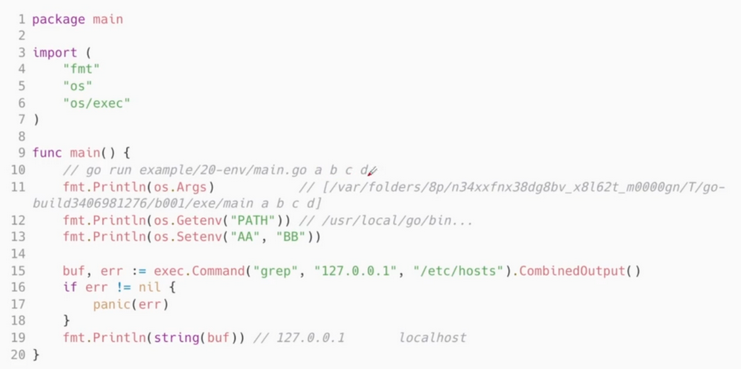
-
os.Argsis used to get theCliparameter. -
os.Getenvandos.Setenvis used to obtain or write into environmental variables.
接下来的东西会使用中文,毕竟有些专有名词或动词我也不知道了
Go语言的实战案例
猜谜游戏
生成随机数
-
导入随机数包
“math/rand” -
使用时间戳初始化随机数种子
-
使用
bufio.NewReader(os.Stdin)将文件转换为一个只读的流 -
使用
strings.TrimSuffix去除从流中读入的换行符
在线词典
-
在开发者工具中抓包
-
复制 curl 并利用工具解析转换成代码
-
分析 Preview 和 Response 并定义对于的构造体
-
可以手搓
-
也可以使用[工具](JSON转Golang Struct - 在线工具 - OKTools)自动生成构造体
-
-
对 Request 进行序列化
-
对 Response 进行反序列化
Socks5
Socks5本身没有对数据进行加密,理论上不能作为魔法代理 🙈,但是…

http的header就不记了,毕竟一般都是用别人封装好了的
Go语言进阶与依赖管理
语言进阶
并发和并行
Go可以发挥多核优势,高效运行
协程和线程
协程:用户态,轻量级线程,栈KB级别
线程:内核态,线程可以并发多个协程,栈MB级别
创建协程
在函数调用的前面,加上 go关键字,即可创建协程
CSP (Communicating Sequential Processes)
这是协程之间的通信
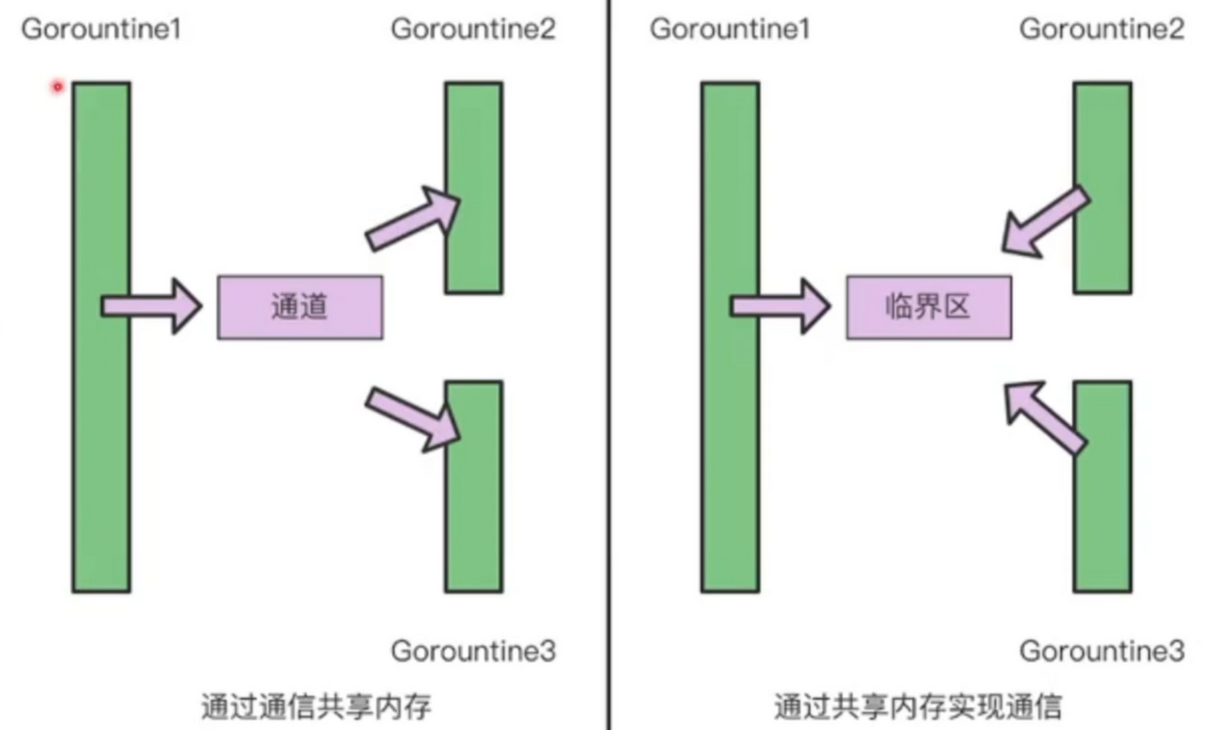
Go语言提倡通过通信共享内存,而不是通过共享内存而实现通信
一般而言,通过共享内存而实现通信的性能较前者弱
Channel
这是一个引用类型,需要使用make关键字创建
包括有缓和无缓通道两类

Lock 并发安全
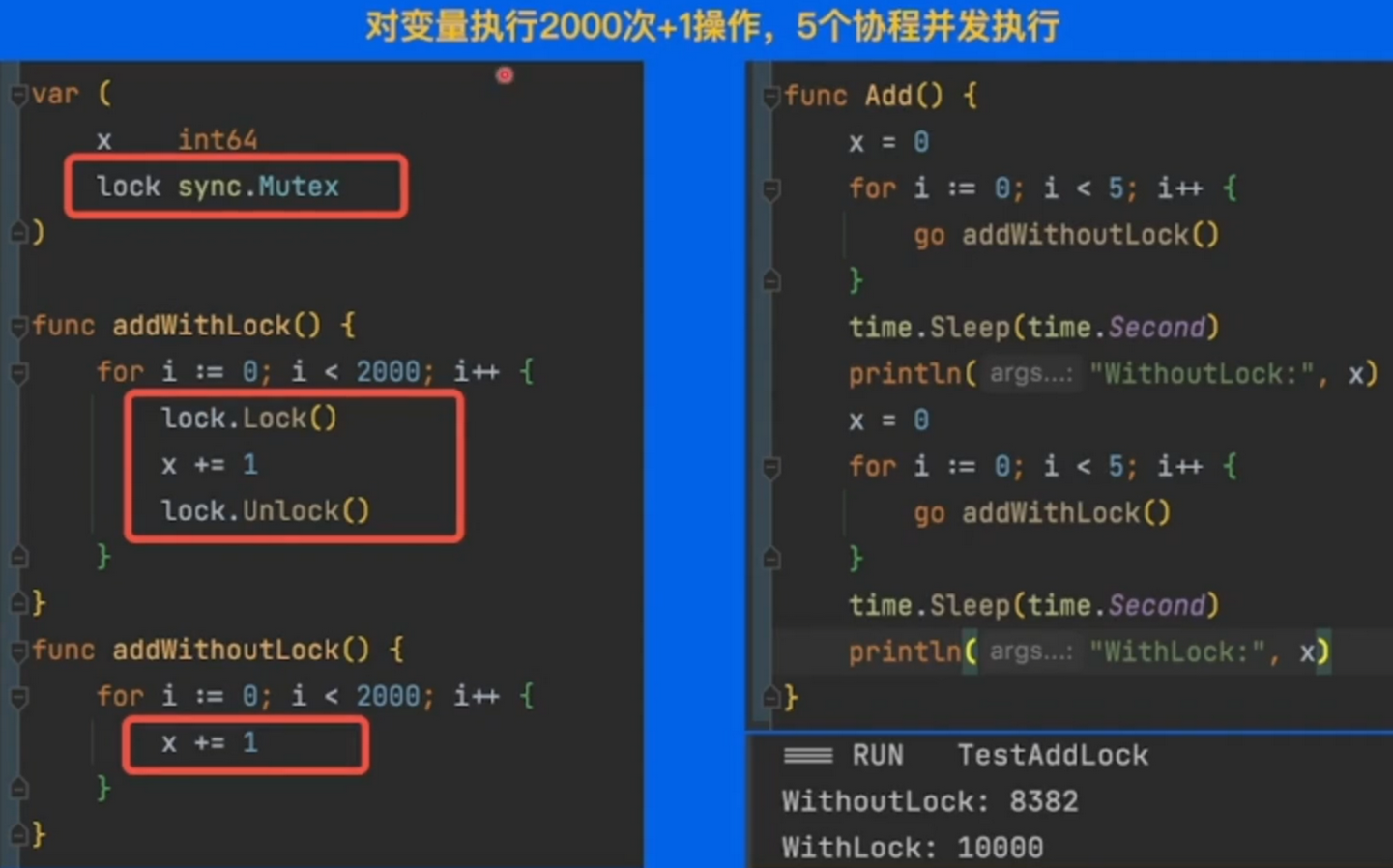
尽量避免对于共享内存进行读写操作
WaitGroup
与 Lock 一样处于 sync 包下
实现并发任务的同步

Go依赖管理
控制依赖库的管理
Go PATH
弊端
当两个项目依赖某一package的不同版本,无发实现package的多版本控制
Go Vendor
通过每个项目引入一份依赖的副本,解决了多个项目需要同一个package的问题
但是
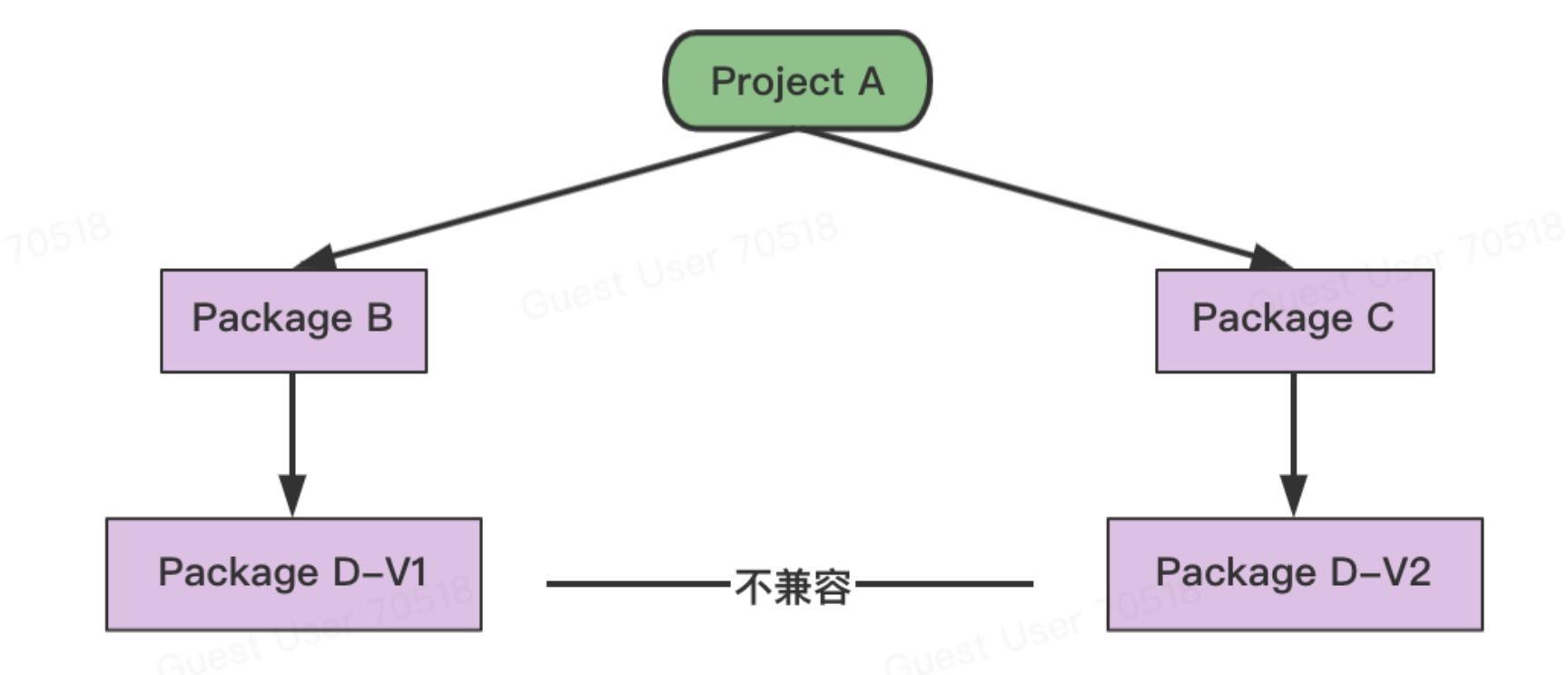 可能导致编译错误
可能导致编译错误
Go Module
通过 go.mod 文件管理依赖包版本
通过 go get/go mod指令工具管理依赖包
可以实现 定义版本规则和管理依赖关系
依赖管理
三要素
1. 配置文件 go mod
2. 中心仓库管理依赖库 Proxy
3. 本地工具 go get/mod
类似于Maven
依赖版本
${MAJOR}.${MINOR}.${PATCH}
MAJOR: 是大版本 各各大版本之间可以不兼容
MINOR: 一般是新增函数和功能
PATCH: 代码bug的修复
Go语言工程实践之测试
单元测试
规范
-
所有测试文件以
_test.go结尾 -
所有测试函数以
func TestXxx (*testing.T)命名 -
初始化逻辑放到
func TestMain(m *testing.M)中
覆盖率
Command
-
go test执行测试 -
--cover返回覆盖率
Tips
-
一般覆盖率:50%~60%;较高覆盖率:80%+
-
测试分支相互独立、全面覆盖
-
测试单元粒度足够小,函数单一职责
Mock测试
外部依赖

外部依赖 => 稳定&幂等
幂等:多次测试结果相同
打桩
monkey: https://github.com/bouk/monkey
进行打桩替换,进而实现不依赖本地文件
基准测试
功能
- 优化代码,需要对当前代码分析
使用
-
Go语言内置测试框架,提供了基准测试的能力
- 用以测试程序性能
-
函数名以
Benchmark开头 -
入参
*testing.B
举例
rand函数
// 随机选择服务器
import (
"math/rand"
)
var ServerIndex [10]int
func InitServerIndex() {
for i := 0; i < 10; i++ {
ServerIndex[i] = i + 100
}
}
func Select() int {
return ServerIndex[rand.Intn(10)]
}
假设我们有10个服务器列表,每次随机选择一个执行

通过测试,我们发现多协程并发测试比穿行测试慢
原因是rand函数为了保证并发安全性和全局随机性,持有一把全局锁
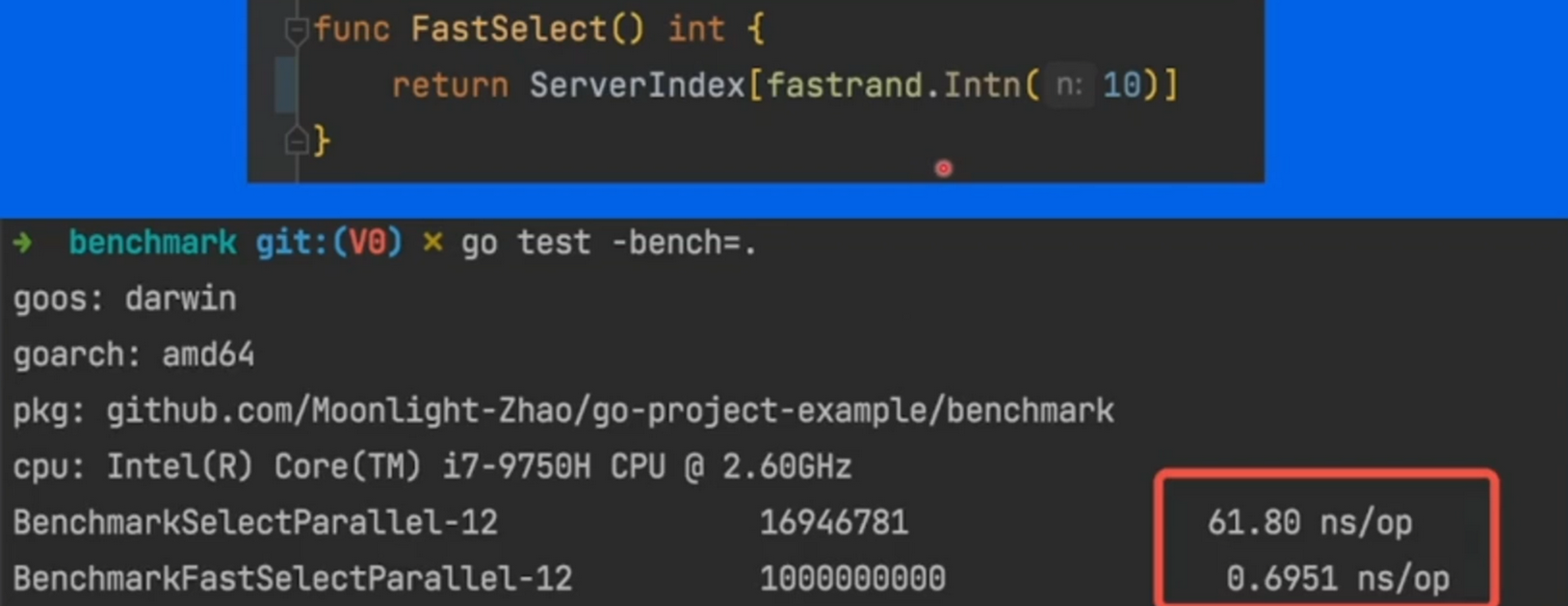
字节为了解决这一随机的性能问题,开源了高性能随机数方法 fastrand
性能提升非常大
思路是牺牲了一定的数列随机性
项目实战
需求分析
需求描述
-
做一个论坛模块
-
展示话题和回帖列表
-
仅实现本地 web 服务
-
话题和回帖用文件的形式存储
ER 图 - Entity Relationship Diagram
Topic
- ID
- Title
- Content
- Poster
- CreateTime
PostList
- ID
- TopicID
- Content
- Poster
- CreateTime
二者之间是一对多的关系
分层结构
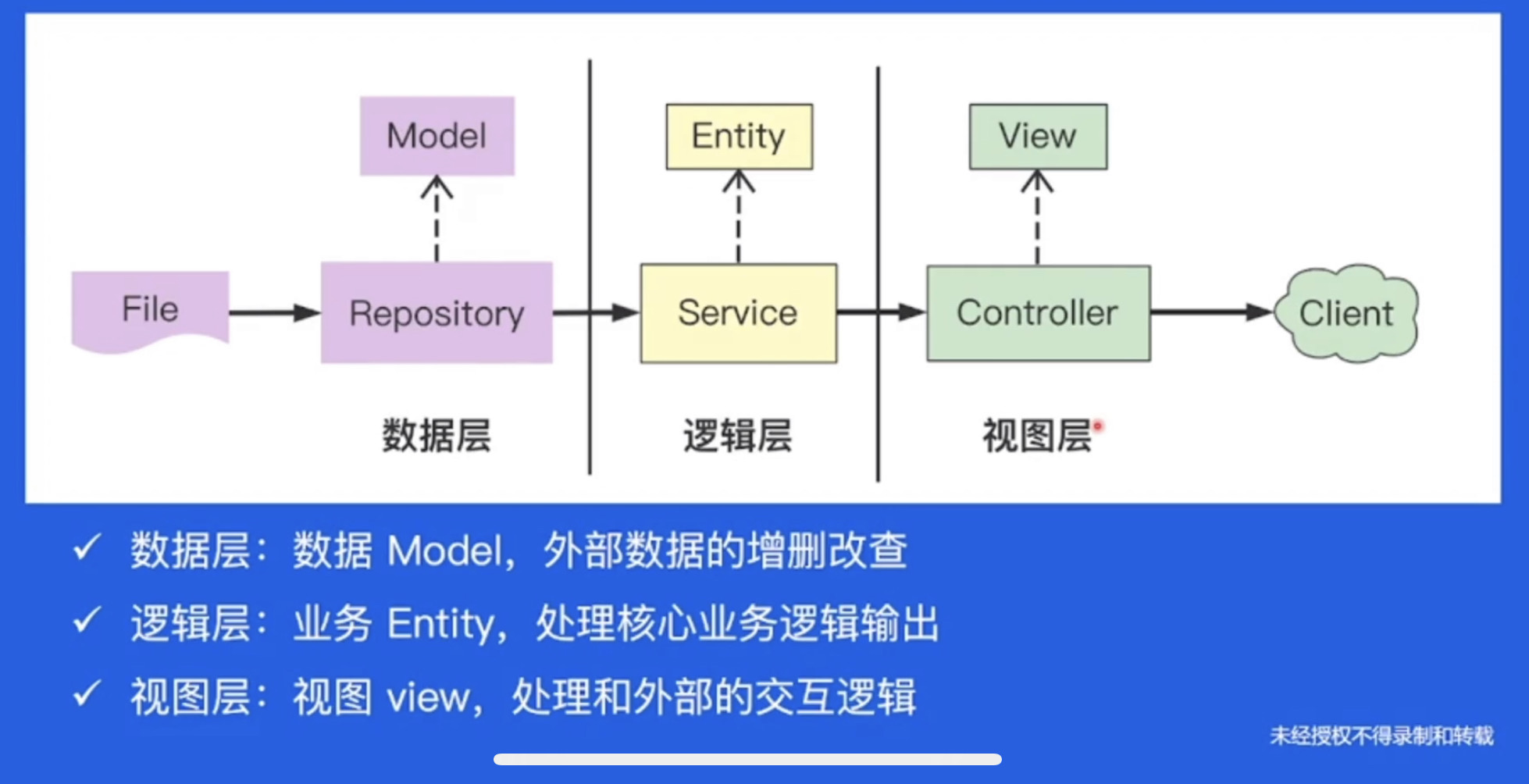
不一定要套用
组件工具
- Gin 高性能 go web 框架
- Go mod
高质量编程简介及编码规范
高质量编程简介
简介
高质量
编写的代码能够达到正确可靠、简洁清晰的目标可以称之为高质量代码
-
边界条件? 完备?
-
异常处理? 稳定性?
-
易读?易维护?
编程原则
简单性
- 消除 “多余的复杂性”,以简单清晰的逻辑编写代码
可读性
-
代码是写给人看的,而不是机器
-
编写可维护代码的第一步是确保代码可读
生产力
- 团队整体工作效率!!!
编码规范
代码格式
-
gofmt
- Go官方自动化Go语言代码为官方统一风格
-
goimports
- 官方工具 + 依赖包管理
注释
注释要做的事情
-
解释代码的作用
-
解释代码如何实现
-
解释代码实现的原因
-
适当解释外部因素
-
提供额外的上下文

-
-
解释代码什么时候会出错
- 解释限制条件
什么时候进行注释
-
声明的每个公共符号:常量、变量、函数以及结构体
-
任何既不简短也不明显的公共功能
-
库中的任何函数
注意
代码是最好的注释
注释应该提供代码未表达的上下文信息
命名规范
变量
-
简洁胜于冗长
-
缩略词全部大写,但当其位于变量开头且不需要导出时,使用全小写
-
例如使用 ServeHTTP 而不是 ServeHttp
-
使用 XMLHTTPRequest 或者 xmlHTTPRequest
-
-
变量距离其使用的地方越远,则需要携带的上下文信息越多
- 全局变量在名字中需要更多的上下文信息
函数
-
函数名不携带包名的上下文信息,因为包名和函数名总是成对出现的
- 例如:
package http func Serve(I net.Listener, handler Handler) error func ServeHTTP(I net.Listener, handler Handler) error -
函数名尽量简短
包
-
只有小写字母构成,不包含大写字母和下划线
-
简短并包括一定的上下文信息
-
不要与标准库同名
控制流程
-
避免嵌套,保持正常流程清晰
-
尽量保持正常代码路径为最小缩进:优先处理错误或特殊情况,尽早返回或继续循环以减少嵌套
- 示例:
//Bad func OneFunc() error { err := doSomething() if err = nil { err := doAnotherThing() if err == nil { return nil } return err } return err }//Good func OneFunc() error { if err := doSomething(); err != nil { return err } if err := doAnotherThing(); err != nil { return err } return err }

错误和异常处理
简单错误
-
仅出现一次,且在其他地方不需要捕获该错误
-
优先使用
errors.New创建匿名变量直接表示简单错误
错误的 Wrap & Unwrap
-
实现了一个错误嵌套另一个错误的功能
-
以便于追踪错误
错误判定
-
error.Is判断错误链上是否包含特定错误 -
error.As获取特定种类的错误
panic
-
不建议在业务代码中使用 panic
-
调用函数不包含 recover 会导致程序崩溃
-
如果问题能够被屏蔽或解决,使用error
-
当程序在启动阶段发生不可逆转的错误时,可以在 init 或 main 函数中使用 panic
revover
-
只能在 defer 的函数中使用
-
无法嵌套
-
只在当前 goroutine 生效
-
多个 defer 语句遵循栈的后进先出原则
小结

我的理解
- 注释和命名简洁但不简陋,要能让其他看代码的人所见即所得
- 一个团队使用同一种代码格式化工具
性能优化建议
简介
-
性能优化的前提是满足正确可靠、简洁清晰等质量因素
-
性能优化是综合评估,有时候时间效率和空间效率可能对立
Benchmark
-
性能的表现要用数据衡量
-
go test -bench=. benchmem -
结果说明:

Slice
Slice 预分配内存
-
尽可能在使用
make()初始化切片时提供容量信息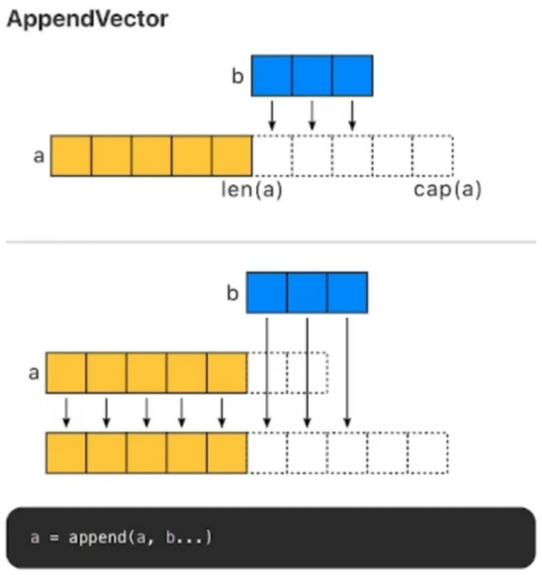
大内存未释放
在已有切片的基础上创建切片,不会更新底层数组
可以使用 copy 代替 re-slice
//re-slice
func getLastBySlice(origin []int) []int {
return origin[len(origin) - 2:]
}
// copy
func getLastByCopy(origin []int ) []int {
result := make([]int, 2)
copy(result, origin[len(origin) - 2:])
return result
}
Map
-
不断向 map 中添加元素的操作会触发 map 的扩容,影响性能
-
可以提前分配空间,以减少内存拷贝和 Rehash 的消耗
-
建议根据实际需求提前预估需要的空间
String
String 的拼接是有讲究的
建议使用 strings.Builder
-
使用 + 拼接的性能是最差的,strings.Builder, bytes.Buffer 相近,而 strings.Builder 更快
-
分析
-
字符串在 Go 语言中是不可变类型,故其占用的内存大小是固定的
- 每次使用 + 都会重新分配内存
-
strings.Builder 和 bytes.Builder 底层都是 []byte 数组
- 由于其内存扩容策略,不需要每次拼接都重新分配内存
-
空结构体
-
空结构体示例不占用任何的内存空间
-
可以作为各种场景下的占位符使用
Atomic 包
在多线程场景中可以维护一个变量:
-
锁的实现是通过操作系统来实现的,属于系统调用
-
atomic 操作是通过硬件实现的,效率比锁高
-
sync.Mutex 应该用于保护一段逻辑,而不仅仅用于保护一个变量
-
对于非数值操作,可以使用 atomic.Value,其能承载一个interface{}
小结
-
避免常见的性能陷阱
-
普通应用代码不要一味追求性能
-
越高级的优化手段越容易出现问题
-
在满足正确可靠、简洁清晰的质量要求的前体现提高程序的性能
疑问
- Atomic包是通过硬件实现的,而Go语言是一个跨平台的语言,它是怎么保证各个平台都能够成功运行的
性能优化分析工具
说在前面
-
性能优化要依据数据
-
要定位最大的瓶颈
-
不要过早优化:当产品迭代时,代码可能会被优化
-
不要过度优化:可能出现无法兼容的问题
性能分析工具pprof
说明
-
可以获取什么地方消耗了多少 CPU、Memory
-
可视化
功能简介
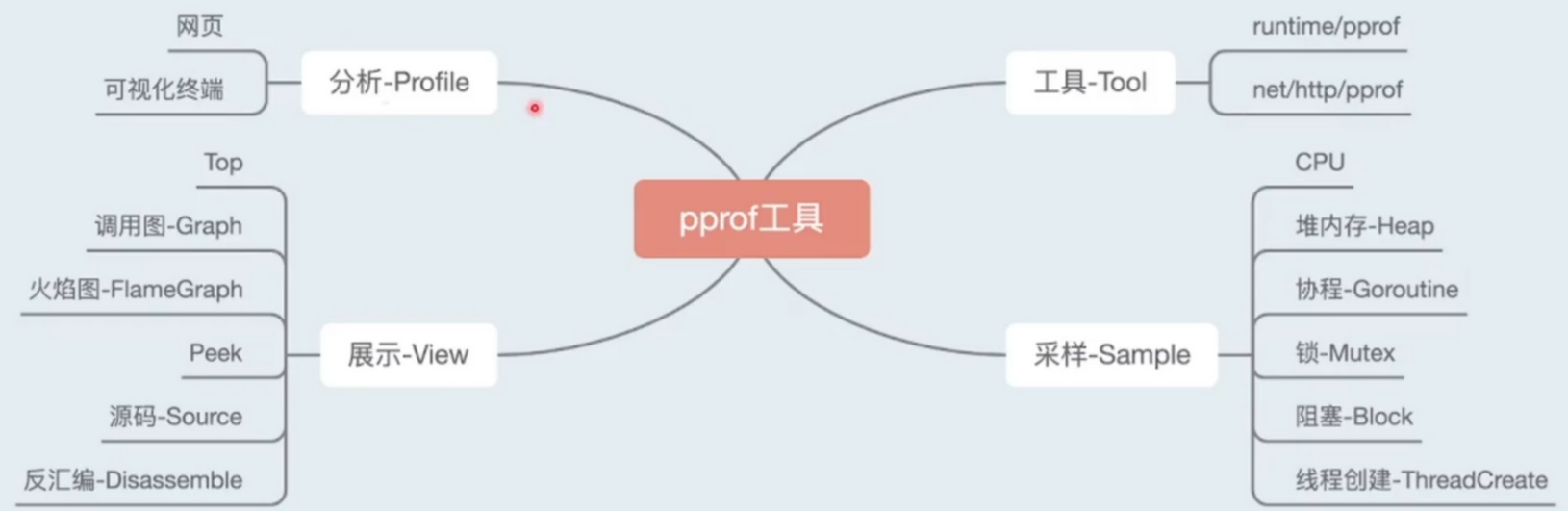
GUI
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/..."
如果出现 Could not execute dot; may need to install graphviz.报错,先前往[graphviz的官网](Download | Graphviz)下载并安装 graphviz
Source 视图
搜索相关问题函数
top指令
对于 CPU 的分析执行 top 指令后会返回如下几个参数:
-
flat => 当前函数本身的执行耗时
-
flat% => flat 占 CPU 总时间的比例
-
sum% => 上面每一行的 flat% 总和
-
cum => 当前函数本身加上其调用函数的总耗时
-
cum% => cum 占 CPU 总时间的比例
Heap
-
alloc_objects 累计申请的对象数
-
alloc_space 累计申请的内存大小
-
inuse_objects 当前持有的对象数
-
inuse_space 当前占用的内存大小
Goroutine
火焰图:
-
由上至下表示调用顺序
-
每一个块表示一个函数,块越长表示占用CPU时间越长
-
火焰图是动态的
其他问题
-
Mutex (锁)
-
Block (阻塞)
-
……
性能优化及自动内存管理
性能优化的层面
业务层优化
-
针对特定的场景,具体问题,具体分析
-
容易获得较大的收益
语言运行时优化
-
解决更加通用的性能问题
-
考虑更多场景
-
Tradeoffs
性能优化与软件质量

-
软件质量至关重要
-
在保证接口稳定的前提下改进具体的实现
-
测试用例:要尽可能覆盖更多的场景,方便回归
-
文档:做了什么,没做什么,能够达到什么效果
-
隔离:通过选项控制是否开启优化
-
可观测:必要的日志输出
自动内存管理
Background
-
动态内存
- 类似于
malloc()
- 类似于
-
垃圾回收
-
避免手动管理内存,专注于实现业务逻辑
-
保证内存使用的正确性和安全性
-
double free problem
-
use-after-free problem
-
-
-
3 Tasks
-
为新对象分配新的空间
-
找到存活的部分
-
回收死亡对象
-
Concept
Basic Concept

评价 GC 算法的角度
-
安全性 (Safety)
-
吞吐量 (Throughput):花在 GC 的时间
-
暂停时间 (Pause Time):业务是否感知
-
内存开销 (Space overhead):GC 元数据开销
BOOK RECOMMEND: “THE GARBAGE COLLECTION HANDBOOK”
追踪垃圾回收 (Tracing garbage collection)
-
回收条件:指针指向关系不可达
-
过程
- 标记根对象
- 静态变量、全局变量、常量、线程栈等
- 标记可达对象
- 求指针指向关系的传递闭包:从根对象出发,找到所有可达对象
- 清理不可达对象
-
将存活对象复制到另外的空间(Copying GC)
- 效率低?
-
将死亡对象的内存标记为“可分配”(Mark-sweep GC)
- 内存碎片?
-
移动并整理存活对象(Mark-compact GC)
- 原地整理
-
根据对象的生命周期,使用不同的标记和清理策略
Generational GC
-
分代假说 (Generational hypothesis): most objects die young
-
Intuition: 很多对象在分配出来后很快不再使用
-
Age: 经历过的 GC 次数
-
目的:对于年轻和年老的对象,指定不同的 GC 策略,以降低整体的内存开销
-
不同年龄的对象处于 heap 的不同区域

-
年轻代
-
常规的对象分配
-
由于存活对象很少,可以采用 copying collection
-
GC 吞吐率很高
-
-
老年代
-
对象趋于一直存活,反复复制开销很大
-
可以采用 marking-sweep collection
-
-
引用记数 (Reference counting)
-
每个对象都有一个与之相关的引用数目
-
存活条件:当且仅当引用数目大于 0
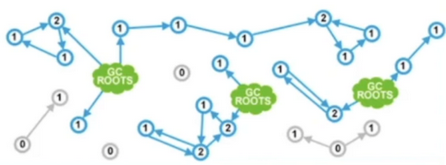
-
优点
-
内存管理操作被平摊到程序操作中

-
内存管理不需要了解 runtime 的实现细节:C++ 的智能指针 (Smart Ponter)
-
-
缺点
-
维护开销大:通过原子操作保证对引用计数操作的原子性和可见性
-
无法回收环形数据结构(weak reference 可以解决这个问题)

-
内存开销:每个对象都引入的额外内存空间存储引用数目
-
回收内存时依然可能引发暂停
-
Go 内存管理 & 编译器优化思路
Go 内存管理
Go 内存分配
-
目标:为对象在 heap 上分配内存
-
实现:提前将内存分块,创建对象时返回尺寸最接近的块
分块
提前将内存分块
-
调用 系统调用 mmap() 向 OS 申请一大块内存,例如 4MB
-
先将内存划分成大块,例如 8KB,称作 mspan
-
再将大块继续划分成特定大小的小块,用于对象分配
-
noscan mspan:分配不包含指针的对象,即 GC 不需要扫描
-
scan mspan:分配包含指针的对象,即 GC 需要扫描
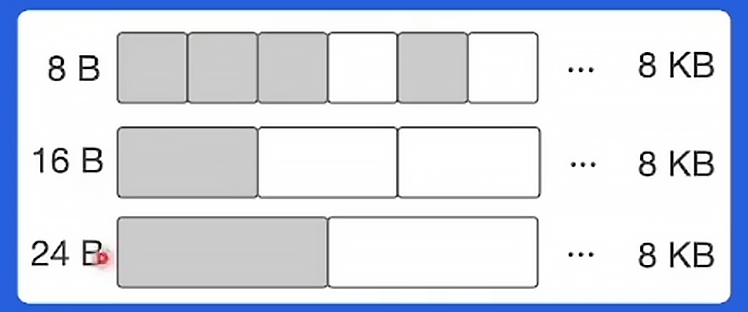
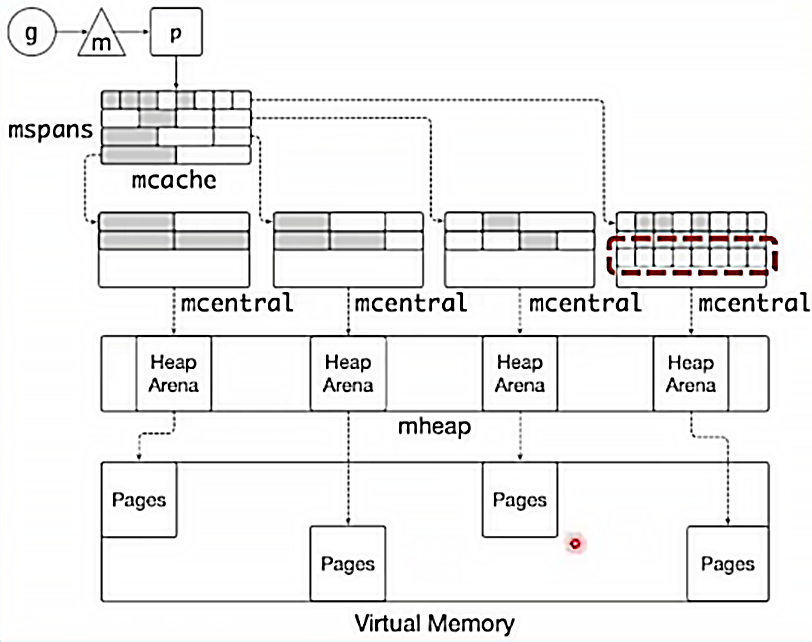
缓存
-
TCMalloc: thread caching
-
每个 p 包含一个 mcache 用于快速分配,为绑定于 p 上的 g 分配对象
-
mcache 管理一组 mspan
-
当 mcache 中的 mspan 分配完毕,向 mcentral 申请带有未分配块的 mspan
-
当 mspan 中没有分配的对象,mspan 会被缓存在 mcentral 中,而不是立刻释放并归还给 OS
优化
思路
-
对象的分配是非常高频的操作:每秒分配 GB 级别的内存(常见
-
同时,小对象占比非常高
-
Go 原本的内存分配比较耗时
- 原因是分配路径长:g -> m -> p -> mcache -> mspan -> memory block -> return pointer
Balanced GC
-
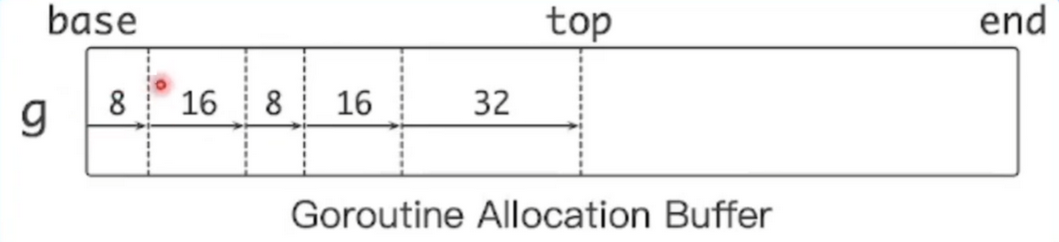
给每个 g 绑定一大块内存(1KB),称作 goruntine allocation buffer (GAB)
-
GAB 用于 noscan 类型的小对象(< 128B)分配
-
使用三个指针维护 GAB:
-
base
-
top
-
end
-
-
指针碰撞(Bump pointer)风格对象分配
-
无须和其他请求互斥
-
分配动作简单高效
if top + size <= end { addr := top top += size return addr }
-
-
细节
-
GAB 对于 Go 内存管理而言是一个大对象
-
本质:将多个小对象的分配合并成一次大对象的分配
-
问题:GAB 的对象分配方式会导致内存被延迟释放

-
方法:移动 GAB 中存活的对象
-
当 GAB 总大小超过一定阈值时,将 GAB 中存活的对象复制到另外分配的 GAB 中
-
原先的 GAB 可以释放,避免内存泄漏
-
本质:用 copying GC 的算法管理小对象(根据对象的生命周期,使用不同的标记和清理策略)

-
-
编译器和静态分析
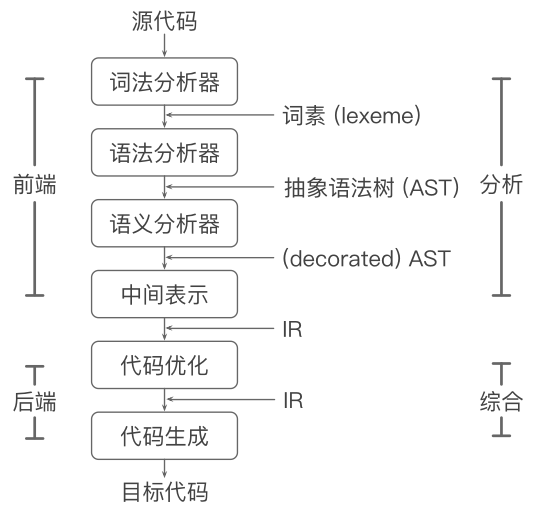
编译器的结构
-
编译器是重要的系统软件
-
识别符合语法和非法的程序
-
生成正确且高效的代码
-
-
分析部分(前端 front end)
-
词法分析,生成词素(lexeme)
-
语法分析,生成语法树
-
语义分析,收集类型信息,进行语义检查
-
中间代码生成,生成 intermediate representation (IR)
- 注意:IR 是机器无关的,即无论是 x86 还是 amd86都能正常运行
-
-
综合部分(后端 back end)
-
代码优化,机器无关优化,生成优化后的IR
-
代码生成,生成目标代码
-
静态分析
-
概念:不执行代码,推导程序的行为,分析程序的性质
-
以一段简单的代码为例
//init int a = 30 int b = 9 - (a / 5) int c c = b * 4 //server if (c > 10) { c = c - 10 } //response return c * (60 / a) -
控制流 (Control flow):程序执行的流程

-
数据流 (Data flow):数据在控制流上的传递

-
通过分析控制流和数据流,我们可以知道更多关于程序的性质 (properties)
- 根据这些性质优化代码
过程内分析和过程间分析
过程内分析
- 仅在过程内部进行分析
过程间分析
-
考虑过程调用时参数传递和返回值的数据流和控制流
-
一般情况,过程间分析需要同时分析控制流和数据流
Go 编译器优化
-
编译器优化的好处
-
用户无感知,重新编译即可获得性能收益
-
通用性优化
-
-
现状
-
Go 的官方编译器采用的优化少
-
由于编译时间较短,没有进行较为复杂的代码分析和优化
-
-
优化思路
-
场景:面向后端的长期执行任务
-
Tradeoff:用编译时间换取更高效的机器码
-
-
Beast mode
-
函数内联
-
逃逸分析
-
默认栈大小调整
-
边界检查消除
-
循环展开
-
……
-
函数内联 (Inlining)
-
概念:将被调用函数的函数体 (callee) 的副本替换到调用位置上 (caller) 上,同时重写代码以反映参数的绑定
-
优点:
-
消除函数调用的开销,例如传递参数、保持寄存器等
-
将过程间分析转换成过程内分析,可以帮助其他优化,例如 “逃逸分析”
-
-
性能测试:micro-benchmark
-
缺点:
-
函数体变大,对于 instruction cache (icache) 不友好
- 容易出现 icache miss
-
编译生成的 Go 镜像变大
-
-
函数内联在大多数情况下是正优化
-
内联策略
-
调用和被调用的规模
-
……
-
Beast Mode
-
Go 函数内联受到的限制较多
-
语言特性,例如 interface, defer 等,限制了函数内联
-
内联策略非常保守
-
-
Beast Mode:调整函数调用的策略,使更多函数内联
-
降低了函数调用的开销
-
增加了其他优化的机会
-
-
开销
-
Go 镜像增加 ~10%
-
编译时间增加
-
逃逸分析
-
概念:分析代码中指针的动态作用域 => 指针在何处可以被访问
-
大致思路:
-
从对象分配处出发,沿着控制流,观察对象的数据流
-
若发现指针p在当前作用域s:
-
作为参数传递给其他函数
-
传递给全局变量
-
传递给其他的 goroutine
-
传递给已逃逸的指针指向的对象
-
-
则指针p指向的对象逃逸出s,反之则没有逃逸出s
-
-
Beast Mode:函数内联拓展了函数的边界,更多对象不逃逸
-
优化:未逃逸的对象可以在栈上分配
-
对象在栈上分配和回收很快:移动 sp
-
减少在 heap 上的分配,降低 GC 负担
-
书刊和论文

我的疑惑
GAB 相当于提前注册了一大块内存,如果 GAB 不饱和是否意味着浪费一大块内存(当时课还没讲到 GAB 延迟释放相关的东西
Go 框架三件套详解
三件套(Gorm, Kitex, Hertz) 介绍
Gorm
迭代了10年的 ORM 的框架,拥有丰富的扩展
Kitex
字节内部的 Golang 微服务 RPC 框架
Hertz
字节内部的 HTTP 框架
三件套的基本使用
Gorm
// Define gorm model
type Product struct {
Code string
Price uint
}
// Define the table name for the model
func (p Product) TableName() string {
return "product"
}
func main() {
// Connect the database
db, err := gorm.Open(
mysql.Open("user:pass@tcp(127.0.0.1:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local",
&gorm.Config{})
if err != nil {
panic("failed to connected database")
}
// Create
db.Create(&Product{Code: "D42", Price: 100})
// Read
var product Product
db.First(&product, 1) // Query product by int
db.First(&product, "code = ?", "D42") // Query product where code == D42
// Update - update the price of products to 200
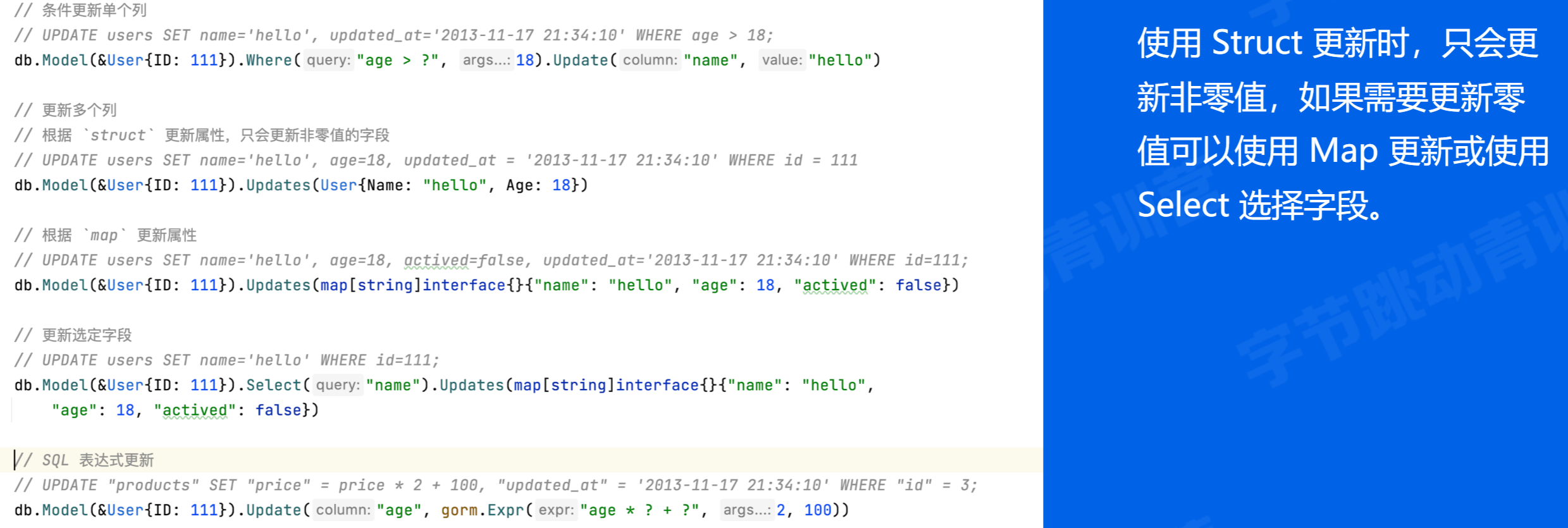
db.Model(&product).Update("Price", 200)
// Update - update many fields
db.Model(&product).Update(Product{Price: 200, Code: "F42"}) // Update non-zero values only
db.Model(&product).Update(map[string]interface{}{Price: 200, Code: "F42"})
// Delete - delete product
db.Delete(&product, 1)
)
}
约定
-
使用名为 ID 的字段作为主键
-
使用结构体的 “蛇形负数“ 作为表名
-
字段的蛇形作为列名
-
使用
CreateAt、UpdateAt字段作为创建、更新时间
数据库支持
-
目前支持 MySQL、SQLServer、PostgreSQL、SQLite
-
通过驱动连接数据库(类似 Spring),如果需要连接其他类型的数据库,可以复用/自行开发驱动
import (
"gorm.io/driver/sqlserver"
"gorm.io/gorm"
)
//dsn: Data Source Name
dsn := "sqlserver://gorm:LoremIpsum86@localhost:9930?database=gorm"
db, err := gorm.Open(sqlserver.Open(dsn), &gorm.Config{})
Gorm 创建数据
package main
import (
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type Product {
ID uint `gorm: "primarykey"`
Code strin `gorm: "column: code"`
Price uint `gorm: "column: user_id"`
}
func main() {
db, err := gorm.Open(mysql.Open( dsn: "username:password@tcp(localhost:9918)/database?charset=utf8"),
&gorm.Config{})
if err != nil : "failed to connect database" *
// Create one line
p := &Product{Code: "D42"}
res := db.Create(p)
fmt.Println(res.Error) // Get err
fmt.Println(p.ID) // Return the main key of the inserted data
// Create many lines
products := []*Product{{Code: "D41"}, {Code: "D42"}, {Code: "D&3"}}
res = db.Create(products)
fmt.Println(res.Error) // Get err
for _, p := products {
fmt.Println(p.ID)
}
}
How to use Upsert
Use clause.OnConflict to deal with data conflict
p := &Product{Code: "D42", ID: 1}
db.Clauses(clause.OnConflict{DoNothing: true}).Create(&p)
Use default value
type User struct {
ID int64
Name string `gorm:"default:galeone"`
Age int64 `gorm: "default:18"`
}
Gorm 查询数据

Gorm 更新数据
Gorm 删除数据

一般情况下使用软删
Gorm 事务
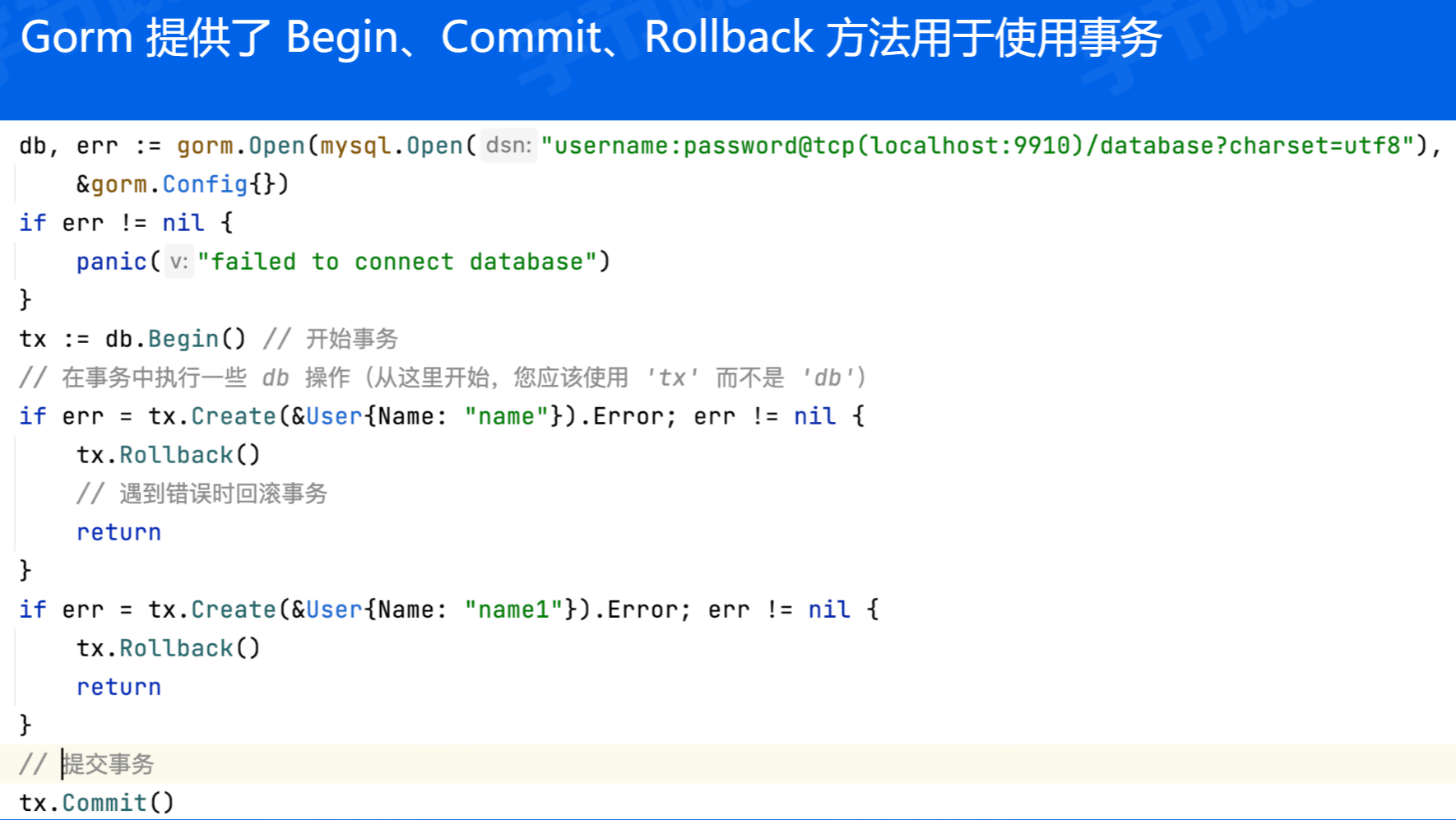
注意:开始事务后,就不是使用 db 而是 tx 了

推荐使用 Transaction 方法
Gorm 链式调用
GORM 允许链式调用,所以可以将多条字句写在一起
例如
db.Where("name = ?", "Lily").Where("age = ?", 18).First(&user)
链式方法是将 Clauses 修改或添加到当前 Statement 的方法,例如:
Where, Select, Omit, Joins, Scopes, Preload, Raw (Raw can’t be used with other chainable methods to build SQL)…
————————————————
原文作者:Go 技术论坛文档:《GORM 中文文档(v2)》
转自链接:https://learnku.com/docs/gorm/v2/method_chaining/9742
版权声明:翻译文档著作权归译者和 LearnKu 社区所有。转载请保留原文链接
Gorm Hook

Gorm 性能提高
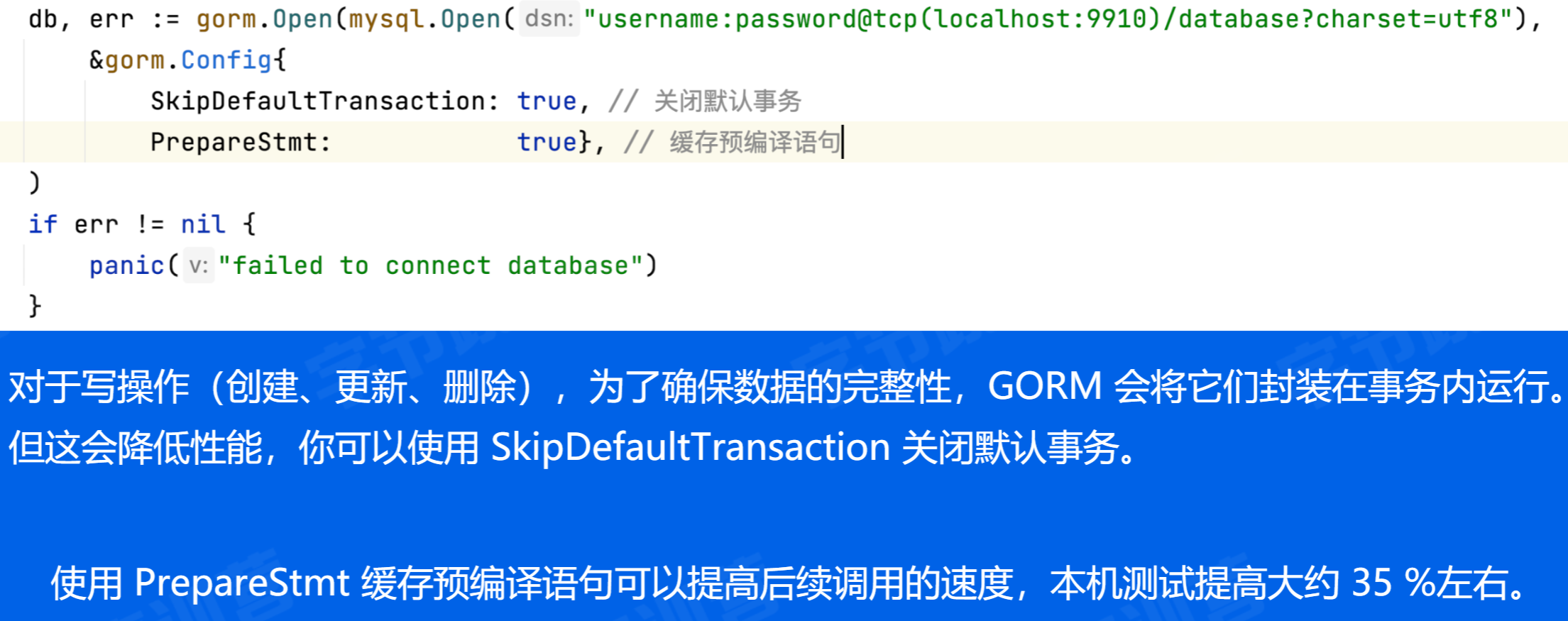
Gorm 生态

Kitex
安装 Kitex
首先,我们需要安装使用本示例所需要的命令行代码生成工具:
确保
GOPATH环境变量已经被正确地定义(例如export GOPATH=~/go)并且将$GOPATH/bin添加到PATH环境变量之中(例如export PATH=$GOPATH/bin:$PATH);请勿将GOPATH设置为当前用户没有读写权限的目录安装 kitex:
go install github.com/cloudwego/kitex/tool/cmd/kitex@latest安装 thriftgo:
go install github.com/cloudwego/thriftgo@latest安装成功后,执行
kitex --version和thriftgo --version应该能够看到具体版本号的输出(版本号有差异,以 x.x.x 示例):$ kitex --version vx.x.x $ thriftgo --version thriftgo x.x.x如果在安装阶段发生问题,可能主要是由于对 Golang 的不当使用造成,请依照报错信息进行检索
定义 IDL(interface description language)
创建一个名为 echo.thrift 的 thrift IDL 文件,然后在里面定义服务

Kitex 生成代码
在完成 IDL 的编写之后,执行一下命令
$ kitex -module example -service example echo.thrift
上述命令中,-module 表示生成的该项目的 go module 名,-service 表明我们要生成一个服务端项目,后面紧跟的 example 为该服务的名字。最后一个参数则为该服务的 IDL 文件

Kitex 基本使用
服务默认监听 8888 端口
编写的服务端逻辑都在 handler.go 这个文件中,示例如下
package main
import (
"context"
"example/kitex_gen/api"
)
// EchoImpl implements the last service interface defined in the IDL.
type EchoImpl struct{}
// Echo implements the EchoImpl interface.
func (s *EchoImpl) Echo(ctx context.Context, req *api.Request) (resp *api.Response, err error) {
// TODO: Your code here...
return
}
简单的需求或代码可以都写着 Echo 里面,如果需求比较复杂,可以参考 MVC 进行分层
Kitex Client 发起请求
创建 Client
import "example/kitex_gen/api/echo"
import "github.com/cloudwego/kitex/client"
...
c, err := echo.NewClient("example", client.WithHostPorts("0.0.0.0:8888"))
if err != nil {
log.Fatal(err)
}
发起请求
import "example/kitex_gen/api"
...
req := &api.Request{Message: "my request"}
resp, err := c.Echo(context.Background(), req, callopt.WithRPCTimeout(3*time.Second))
if err != nil {
log.Fatal(err)
}
log.Println(resp)
Kitex 服务发现与注册
Kitex 框架提供服务注册与发现的扩展,目前已经支持与业界主流注册中心对接。
服务注册
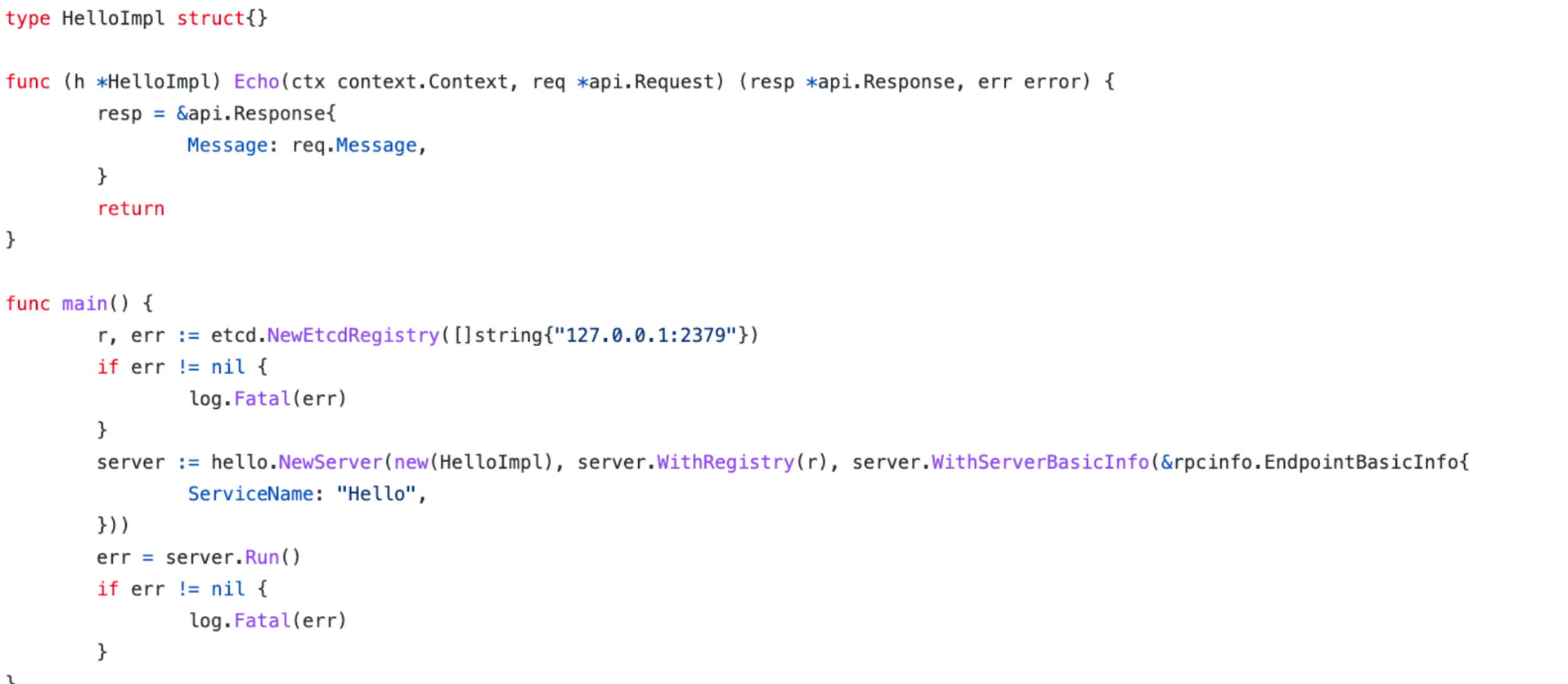
服务发现

Kitex 生态
Kitex 扩展非常丰富,下面是一些常用的扩展

- XDS 流量路由
Hertz
基本使用

-
server.Default 默认继承 recover 中间件
-
server.New 默认不继承 recover 中间件
-
h.GET 有两个上下文,一个专注于 “内容”,一个专注于 “请求的处理”
Hertz 路由
注册路由
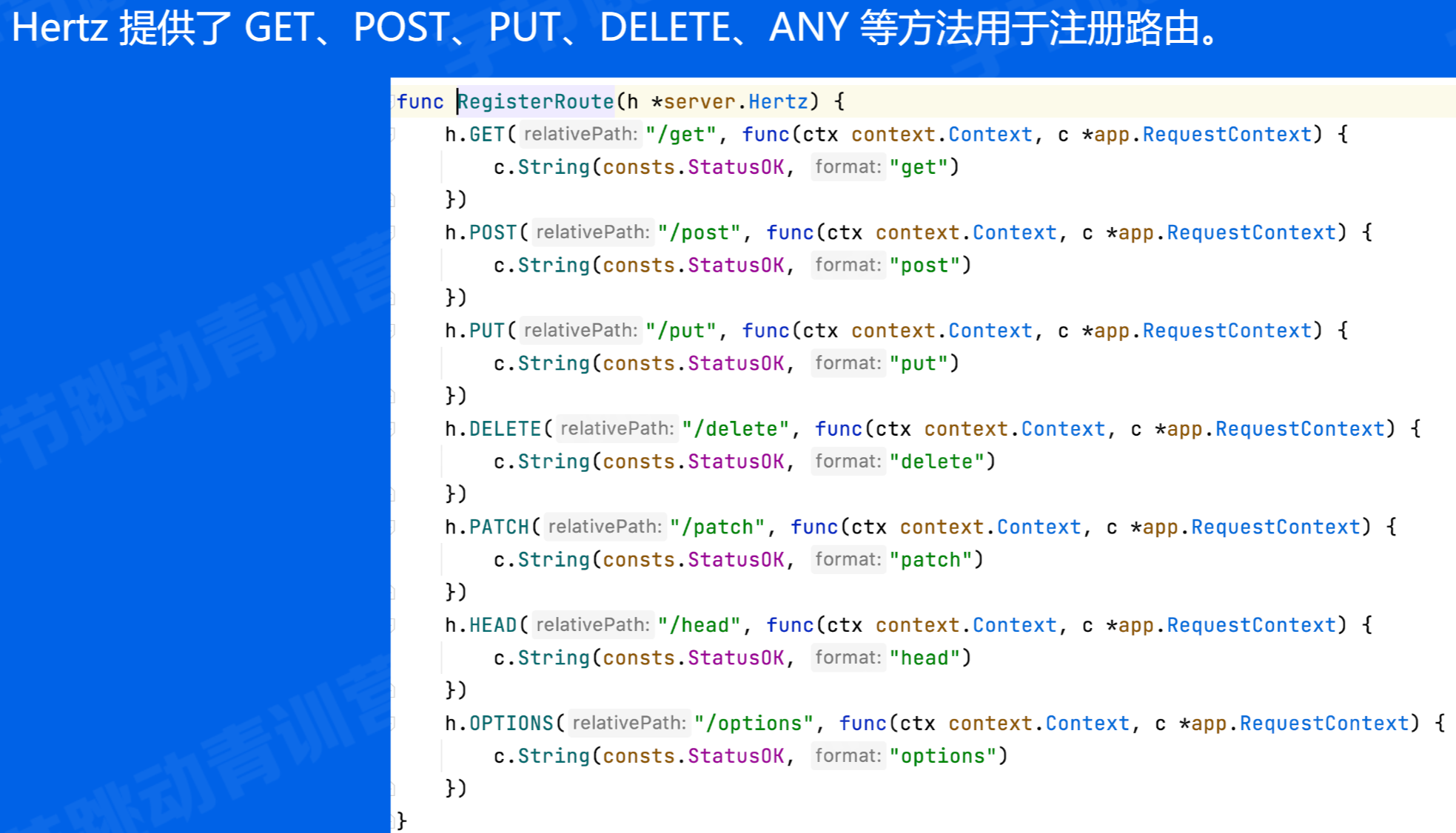
也可以使用:HANDLE 方法以使用自定义路由
路由组

动态路由
Hertz 提供了参数路由和通配路由

当一个请求同时命中多个路由时,存在路由优先级:
静态路由 > 命名路由 > 通配路由
参数绑定

中间件
-
分为客户端中间件和服务端中间件
-
当存在通用的逻辑时,比如打印日志、计算接口耗时、源信息的设置和传递,会使用中间件
-
这里是 一个服务端中间件:
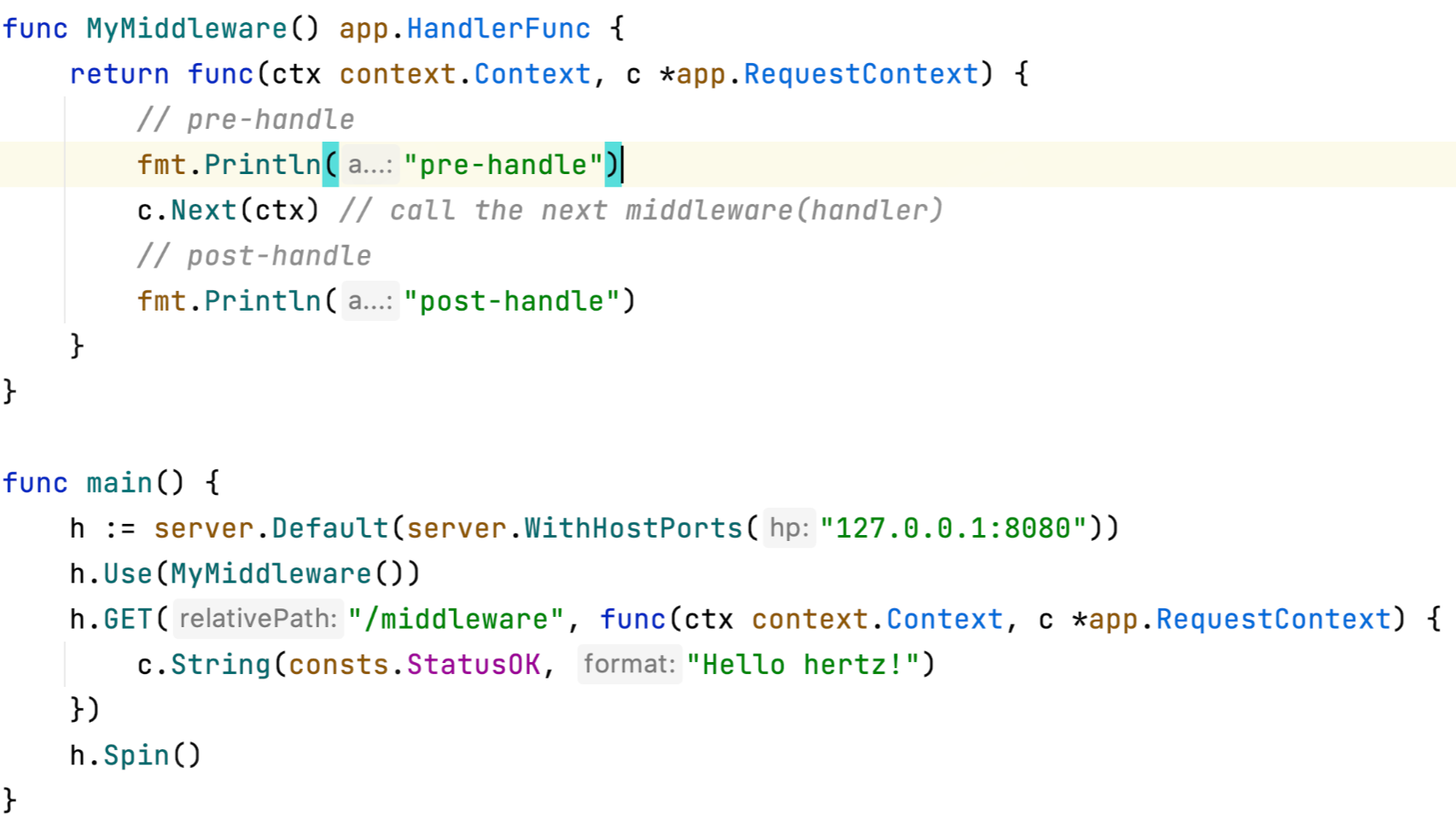
-
终止中间件调用链的执行:
-
c.Abort
-
c.AbortWithMsg
-
c.AbortWithStats
-
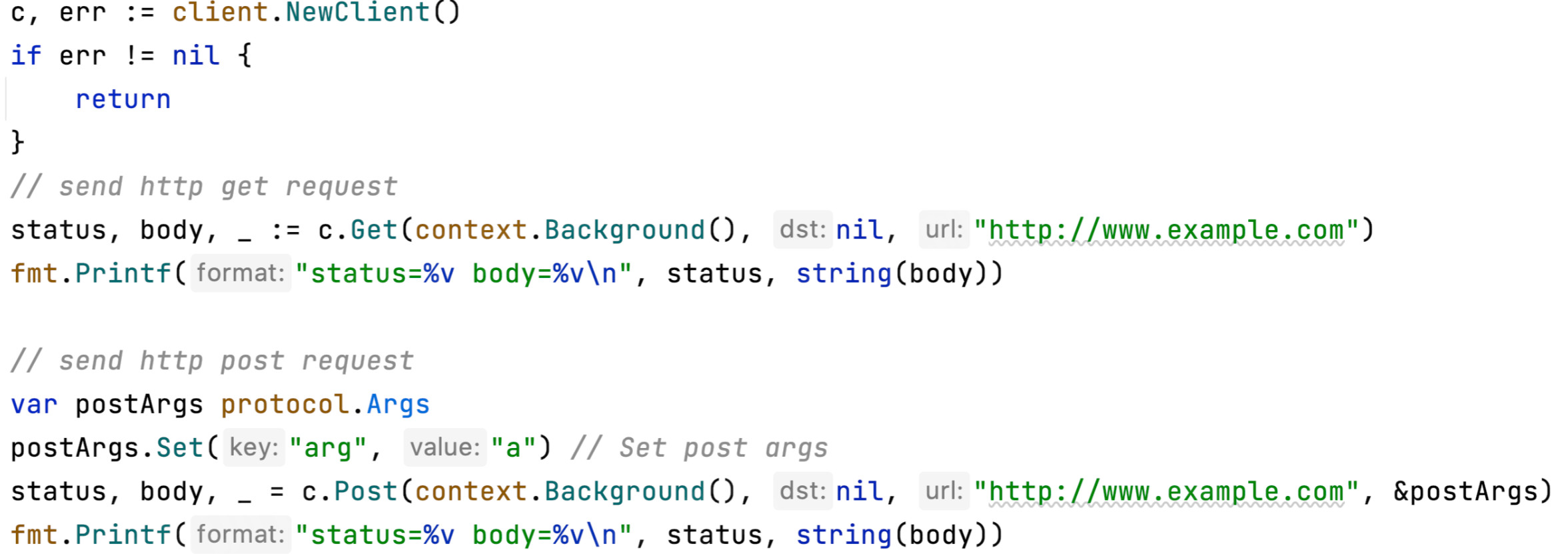
HTTP Client
Hertz 提供 HTTP Client 用于帮助用户发送 HTTP 请求
这是一个 Client 的 GET 和 POST 请求示例:
Hz 代码生成工具
基本使用
-
通过定义 IDL 文件即可生成对应的基础服务端代码,新版支持生成 Client 代码(客户端代码)

目录结构

model 包下对应的是 结构体
router 包下提供一些方便注册中间件和路由的代码逻辑
性能
-
网络库:Netpoll
- 在小包场景优于标准库
-
Json 编解码:Sonic
-
使用 sync.Pool 复用对象协议层数据解析优化
Some of the pictures come from the network, and please contact me if there is any infringement.